Playing Words with Friends
Words with Friends
Words with Friends, if you're not already familiar, is a game of Scrabble that lets you play asynchronously with friends over the internet.
I recently started playing WoF because I like to think I have a large vocabulary and rarely get the opportunity to use it. I also enjoy playing boardgames like Scrabble but between work and ... sleep... I don't often get the chance to get together with my friends and play Taluva into the wee hours.
Anyway, I have a confession to make.
I'm terrible at Words with Friends
Whenever it is my turn I look at my hand of letters: ILNIREE
And think: ILNIREE is not a word. Darn.
And then I start to mentally rearrange letters to see if I can make other words. WoF's conveniently includes a "Shuffle" button so I hit that a few times... And while given enough time I do come up with a word a few things bug me about this process.
First of all, years of Google and Wikipedia use have atrophied important muscles like "memory". Second, i'm a programmer and that means:
Laziness1
Basically shuffling letters and checking or guessing that they are words is a perfectly straightforward although not terribly efficient way to try to optimize your scrabble game. Of course, it's got a lot of drawbacks if you try to do it by hand. It's slow and it's uninteresting. To try to find every word possible with any of your 7 letters you'd need to try all permutations and there are over 10,000 permutations of 7 letters.
Anyway, I'm bad at Words with Friends but I like programming so once I started playing WoF of course I gravitated towards...
Solving Words with Friends2
Boring and repetitive work is exactly what computers are good at it! In fact the Python program to generate all possible permutations of 7 letters (1 letter words, 2 letter words, 3 letter words, etc) is pretty straightforward especially with a little help from our friend itertools.
My first and simplest attempt involved putting the contents of the standard unix dictionary (/usr/share/dict/words) into a python dictionary (an excellent hash table implementation).
This isn't exactly what I came up with first but it should illustrate what I'm talking about:
Of course you end up looking at a lot of permutations for 7 letters (~13 thousand) so this can take a little while. It's still not slow on any reasonable computer but when you start adding in other letters to try and find words that might fit in with available spots on the board things can slow down. For example, say you could play words that begin with t, l, or r. Running the above getScrabbleLetters function for 10 letters requires you to check 9,864,101 permutations.
Worse still, if you add in the notion of wildcards (9 letters plus some character like '*' to represent a wildcard) you end up repeating those over 9 million lookups 26 times to check all the other possible letters of the alphabet in the wildcard slot. That's over 250 million dictionary lookups to find a fairly small list of unique words.
However, if we step back for a moment and think about anagrams, a simple tweak can help process larger strings (and strings with wildcards) much more quickly.
Imagine you've got a couple anagrams like "was" and "saw". They've got the same letters but count as two different words in our dictionary and require two separate lookups. If we shift our perspective a little bit and start thinking about the letters as what's important we get some very nice performance improvements.
We still use a hash table as our primary data structure but instead of using the words as the keys we use the sorted letters of a word as the key. The values become lists of all the words which include those same letters. It's a little bit more work to insert, as we first have to calculate what the key would be, and it's a little more work to lookup, as we have to iterate over the list of possible words. But it's great any time we care just about anagrams and it's much more efficient in terms of the number of lookups required to find all the scrabble words. For example, for the same 10 letter case from earlier we now need only 1024 lookups. ~26 thousand lookups for the wildcard case.
Without further ado that solution looks like this:
One other really useful bit is a quick way to look for all the words that have a given suffix or prefix. This is a little trickier than the anagram case but it's also more interesting because I got to spend a little time reading about a new data structure, a Trie. A Trie is a tree-like structure optimized for storing strings. The root node of the tree represents the empty string and each of its children represents the first letter of a word. Every child of these nodes is the next letter in a word starting with that substring.
For example, a trie of nodes for the words "an apple yum" would look like:
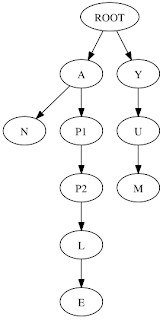
So the trie solution for finding words that begin with a certain prefix is:
The suffix version is just a couple more lines with judicious use of the reversed function.
Conclusion and Next Steps
I think that Words with Friends is a lot more fun now that I have my computer as a crutch. I've enjoyed playing with some simple algorithms for finding algorithms and looking up strings.
My next steps after today are going to be putting up my utilities here on my website so that I can share them with my non-programmer friends. Building a simple web service for solving/cheating at scrabble is a hopefully interesting topic in its own right so building that will probably be my next blog post.
After that I'm interested in taking this to its logical conclusion and actually building (and blogging about) a scrabble solver where you can enter in the whole state of the scrabble board and your hand and have it tell you all your possible moves (or at least the subset of moves that give you higher scores).
If you made it this far you might be interested in the actual tested source code here on github.
1
Words with Friends, if you're not already familiar, is a game of Scrabble that lets you play asynchronously with friends over the internet.
I recently started playing WoF because I like to think I have a large vocabulary and rarely get the opportunity to use it. I also enjoy playing boardgames like Scrabble but between work and ... sleep... I don't often get the chance to get together with my friends and play Taluva into the wee hours.
Anyway, I have a confession to make.
I'm terrible at Words with Friends
Whenever it is my turn I look at my hand of letters: ILNIREE
And think: ILNIREE is not a word. Darn.
And then I start to mentally rearrange letters to see if I can make other words. WoF's conveniently includes a "Shuffle" button so I hit that a few times... And while given enough time I do come up with a word a few things bug me about this process.
First of all, years of Google and Wikipedia use have atrophied important muscles like "memory". Second, i'm a programmer and that means:
Laziness1
Basically shuffling letters and checking or guessing that they are words is a perfectly straightforward although not terribly efficient way to try to optimize your scrabble game. Of course, it's got a lot of drawbacks if you try to do it by hand. It's slow and it's uninteresting. To try to find every word possible with any of your 7 letters you'd need to try all permutations and there are over 10,000 permutations of 7 letters.
Anyway, I'm bad at Words with Friends but I like programming so once I started playing WoF of course I gravitated towards...
Solving Words with Friends2
Boring and repetitive work is exactly what computers are good at it! In fact the Python program to generate all possible permutations of 7 letters (1 letter words, 2 letter words, 3 letter words, etc) is pretty straightforward especially with a little help from our friend itertools.
My first and simplest attempt involved putting the contents of the standard unix dictionary (/usr/share/dict/words) into a python dictionary (an excellent hash table implementation).
This isn't exactly what I came up with first but it should illustrate what I'm talking about:
Of course you end up looking at a lot of permutations for 7 letters (~13 thousand) so this can take a little while. It's still not slow on any reasonable computer but when you start adding in other letters to try and find words that might fit in with available spots on the board things can slow down. For example, say you could play words that begin with t, l, or r. Running the above getScrabbleLetters function for 10 letters requires you to check 9,864,101 permutations.
Worse still, if you add in the notion of wildcards (9 letters plus some character like '*' to represent a wildcard) you end up repeating those over 9 million lookups 26 times to check all the other possible letters of the alphabet in the wildcard slot. That's over 250 million dictionary lookups to find a fairly small list of unique words.
However, if we step back for a moment and think about anagrams, a simple tweak can help process larger strings (and strings with wildcards) much more quickly.
Imagine you've got a couple anagrams like "was" and "saw". They've got the same letters but count as two different words in our dictionary and require two separate lookups. If we shift our perspective a little bit and start thinking about the letters as what's important we get some very nice performance improvements.
We still use a hash table as our primary data structure but instead of using the words as the keys we use the sorted letters of a word as the key. The values become lists of all the words which include those same letters. It's a little bit more work to insert, as we first have to calculate what the key would be, and it's a little more work to lookup, as we have to iterate over the list of possible words. But it's great any time we care just about anagrams and it's much more efficient in terms of the number of lookups required to find all the scrabble words. For example, for the same 10 letter case from earlier we now need only 1024 lookups. ~26 thousand lookups for the wildcard case.
Without further ado that solution looks like this:
One other really useful bit is a quick way to look for all the words that have a given suffix or prefix. This is a little trickier than the anagram case but it's also more interesting because I got to spend a little time reading about a new data structure, a Trie. A Trie is a tree-like structure optimized for storing strings. The root node of the tree represents the empty string and each of its children represents the first letter of a word. Every child of these nodes is the next letter in a word starting with that substring.
For example, a trie of nodes for the words "an apple yum" would look like:
So the trie solution for finding words that begin with a certain prefix is:
The suffix version is just a couple more lines with judicious use of the reversed function.
Conclusion and Next Steps
I think that Words with Friends is a lot more fun now that I have my computer as a crutch. I've enjoyed playing with some simple algorithms for finding algorithms and looking up strings.
My next steps after today are going to be putting up my utilities here on my website so that I can share them with my non-programmer friends. Building a simple web service for solving/cheating at scrabble is a hopefully interesting topic in its own right so building that will probably be my next blog post.
After that I'm interested in taking this to its logical conclusion and actually building (and blogging about) a scrabble solver where you can enter in the whole state of the scrabble board and your hand and have it tell you all your possible moves (or at least the subset of moves that give you higher scores).
If you made it this far you might be interested in the actual tested source code here on github.
1
- Larry Wall calls this the first great virtue of a programmer.
- 2
- Perhaps a more honest heading here would be "Cheating at Words With Friends" :-)